I have enjoyed speaking at the unconference very much. I chose not to use anything else than a SQL file to demonstrate the capabilities.
Thanks to the audience for coming. Here is the SQL file I used for the demo
I have enjoyed speaking at the unconference very much. I chose not to use anything else than a SQL file to demonstrate the capabilities.
Thanks to the audience for coming. Here is the SQL file I used for the demo
SQL Model – Oracle Wiki
My unconference is Thursday at 2pm
I just arrived at San Francisco and meet my colleague Daniel and Lutz Hartmann. Thanks Dani for driving us to SF and thanks Lutz for the Indian food in the restaurant where we ended last year during Blogger 2006 Meetup 🙂 . By the way do not miss 2007 Meetup organized by Mark Rittman : oow 2007 blogger meetup
I took the cable car from Lutz hotel to the Fishermann’s Wharf. Here it is raining, but well, in Zurich it was snowing and the wind was so cold that they needed to unfreeze the aisles of the plane before take off!
In less than 8 hours the 11g exam cram is starting at Moscone South 104 ! My notebook clock is still set to Sun Nov 11, 10:10 am, I will try to sleep until 7am…
I exported to CSV, formated and printed my schedule
I will have to add the Unconferences too.
Saturday I have a long long day to flight to San Francisco 😎
On Sunday you can assist to the 11g exam cram from 9am to 5pm. It may be too late to register, I tried anyway :
11g db Exam Cram
Then you may want to get your OCP credentials for a discount price.
on-site testing
The Oracle Database 11g New Features for Administrators exam will be available in beta version during the conference. Beta exams are not available at Oracle OpenWorld 2007.
If I read this correctly, it means 11g New Features is available during the conference but not at the conference 😯
Dear Friends,
Planning to appear for Oracle DB 10g: Administration I exam, Would be very grateful if you send across braindumps/questions/tips related to that.
Pl mail to this id : ***@yahoo.com
Many Thanks,
***
When I appeared to my first multiple choice question exam by Prometrics back in 1997, there were no brain dumps, no free question except the 10 sample questions on the vendor site, and no book. I missed Sun JDK 1.0.2 exam because of the many questions related to java.media.Player and other classes totally unknown to me.
In 2000, I did OCP 8.0 and 8i. That was 5 exams. One of the exam was called Oracle 8.0 Network. I had and I still have never used connection pooling, Oracle Names, Oracle Connection Manager.
So I bought a book to prepare for the certification :

Guess what, I mastered that exam. Those books are fairly useless, you do not really learn something, but you learn questions by heart and passing an exam on a topic you do not know is dramatically easy.
On the Internet, there are hundreds of vendors that sell exam questions. Oracle itself has a kind of partnership with SelfTestSoftware. SelfTestSoftware is an official vendor of test simulators. Well, why paying 99$ for a test? A new trend is to post on the official Oracle Technical Network Certification Forum your email address and beg for free questions. I have alerted ocpfraud_ww@oracle.com about this behaviour.
Is OCM better? Well, at least you must know how to use your fingers to type quickly. I received not less than 50 emails from people asking for the content of the exam.
I passed the OCM in early 2004. Later in 2004, former Oracle Certification Principal Jim DiIanni revealed the content of the Practicum in Oracle Magazine 😯
Recently I did the Oracle Certification Experts beta exams for RAC and SQL. Those exams are also multiple choice tests and could also be a market for illegal certification sites.
If you want to pass the 11g New Features exam, you could also attend to a new feature course.
In OpenWorld next week there are also some mini-lessons from Oracle University like :
Oracle Database 11g: Can I Do That? Introducing 11g SQL and PL/SQL Enhancements
Oracle Ace Lutz Hartmann is giving 11g courses in Switzerland : http://sysdba.ch/aktuell.php
I am in the processing in adding logfiles to a 10gR2 database.
SQL> alter database add logfile group 10 size 1e7;
Database altered.
$ ls -l
-rw-r----- 1 oracle 10000896 Nov 1 15:00
o1_mf_10_3lmq05ld_.log
The file size is 10,000,896 bytes.
What about this :
SQL> alter database drop logfile group 10;
Database altered.
SQL> alter database add logfile size 1e;
alter database add logfile size 1e
*
ERROR at line 1:
ORA-00741: logfile size of (2251799813685248) blocks
exceeds maximum logfile size
No way! Oracle does not want me to add a logfile of 1 Exabyte !
Remember the logfile blocks are OS blocks of 512 bytes. Not Oracle blocks.
Ok, let’s try something else
SQL> alter database add logfile size 1p;
alter database add logfile size 1p
*
ERROR at line 1:
ORA-00741: logfile size of (2199023255552) blocks
exceeds maximum logfile size
No, one Petabyte is not a realistic size for a log file.
I have one more try, but unfortunately it works 👿
SQL> alter database add logfile size 1t;
...
It just takes ages…
$ ls -l
-rw-r----- 1 oracle dba 1099511628288 Nov 1 14:49
o1_mf_5_3lmpb6w6_.log
$ du -g o1_mf_5_3lmpb6w6_.log
6.09 o1_mf_5_3lmpb6w6_.log
$ df -gt .
Filesystem GB blocks Used Free %Used Mounted on
/dev/u02_lv 140.00 19.32 120.68 14% /u02
The ls shows the file size has been set to 1T and 6 Gigabytes have been allocated yet. Since I do not want to fill my filesystem, I just shutdown-abort my instance and remove that file…
I posted about Unexpected results in June 2005. Here are more results from NOT IN and NULL
select * from dual
WHERE (1) NOT IN (SELECT NULL FROM DUAL);
no rows selected
select * from dual
WHERE (1,1) NOT IN (SELECT NULL,1 FROM DUAL);
no rows selected
However, and this surprised me,
select * from dual
WHERE (1,1) NOT IN (SELECT NULL,2 FROM DUAL);
D
-
X
🙄
Probably the expression
where (a,b) not in (select c,d from t)
is translated into
where (a!=c or b!=d) — first row of t
and (a!=c or b!=d) — second row of t
— and …
What is doing the MIN(DISTINCT X) call? Basically, every distinct value of X is passed to the MIN function. Well, it is probably of very little interest as the MIN function is very fast and processing less rows than MIN(X) should not boost the performance because of the overhead of sorting distinct values.
However, if you write your own aggregate, distinct may be interesting!
create type myudag_type as object
(
myudag INTEGER,
static function ODCIAggregateInitialize(
sctx IN OUT myudag_type)
return number,
member function ODCIAggregateIterate(
self IN OUT myudag_type,
value IN INTEGER)
return number,
member function ODCIAggregateTerminate(
self IN myudag_type,
returnValue OUT INTEGER,
flags IN number)
return number,
member function ODCIAggregateMerge(
self IN OUT myudag_type,
ctx2 IN myudag_type)
return number
);
/
create or replace type body myudag_type is
static function ODCIAggregateInitialize(
sctx IN OUT myudag_type)
return number is
begin
sctx := myudag_type(0);
return ODCIConst.Success;
end;
member function ODCIAggregateIterate(
self IN OUT myudag_type,
value IN INTEGER)
return number is
begin
-- doing nothing will cost you a lot !!!
for i in 1..1000000 loop null; end loop;
return ODCIConst.Success;
end;
member function ODCIAggregateTerminate(
self IN myudag_type,
returnValue OUT INTEGER,
flags IN number) return number is
begin
returnValue := self.myudag;
return ODCIConst.Success;
end;
member function ODCIAggregateMerge(
self IN OUT myudag_type,
ctx2 IN myudag_type)
return number is
begin
return ODCIConst.Success;
end;
end;
/
CREATE FUNCTION myudag (
input INTEGER)
RETURN INTEGER
AGGREGATE USING myudag_type;
/
SQL> select myudag(deptno) from emp;
MYUDAG(DEPTNO)
--------------
0
Elapsed: 00:00:00.57
SQL> select myudag(distinct deptno) from emp;
MYUDAG(DISTINCTDEPTNO)
----------------------
0
Elapsed: 00:00:00.13
10.2.0.4 should be available this year on Linux x86. Check Metalink Certification for different plateforms.
Certify – Additional Info Oracle Database – Enterprise Edition Version 10gR2 On Linux (x86)
Existing patch sets:
10.2.0.2
10.2.0.3
10.2.0.4 Q4CY2007
Yesterday I installed ContentDB. The installation is fairly straightforward.
Download and install Oracle Identity Management
This will create a 10.1.0.5 database. The default parameters are too low for contentDB.
alter system set
processes=250
scope=spfile
sga_max_size=629145600
scope=spfile
shared_pool_size=184549376
scope=spfile
java_pool_size=125829120
scope=spfile
db_cache_size=150994944
scope=spfile
db_file_multiblock_read_count=32
scope=spfile
db_create_file_dest='/u02/oradata'
scope=spfile
job_queue_processes=10
scope=spfile
session_max_open_files=50
scope=spfile
open_cursors=400
scope=spfile
star_transformation_enabled=true
scope=spfile
pga_aggregate_target=203423744
scope=spfile;
It is recommended to stop the application server infrastructure before restarting the database to make the parameters above effective.
$ $ORACLE_HOME/bin/emctl stop iasconsole
$ $ORACLE_HOME/opmn/bin/opmnctl stopall
$ sqlplus / as sysdba
SQL> shutdown immediate
SQL> startup
$ $ORACLE_HOME/opmn/bin/opmnctl startall
$ $ORACLE_HOME/bin/emctl start iasconsole
It is now possible to install ContentDB in this database. Of course the ContentDB could be installed in a separate database, it does not have to be the same as the infrastructure database.
Now, download and install Oracle ContentDB
That’s all. There now two application server instances, one for the infrastructure and one for the content database.
To launch the Content Database web interface, just go to the http server of the ContentDB installation, something like http://server:7779.
$ /app/oracle/product/10.1.2/cdb_1/bin/opmnctl status -l
Processes in Instance: CONTENTDB01.srv01
-------------------+----------+------------------------
ias-component | status | ports
-------------------+----------+------------------------
DSA | Down | N/A
HTTP_Server | Alive | http1:7779,http2:7202
LogLoader | Down | N/A
dcm-daemon | Alive | N/A
OC4J | Alive | ajp:12503,rmi:12403,...
WebCache | Alive | http:7778,invalidati...
WebCache | Alive | administration:9400
Content | Alive | node_dms_http:53900,...
Content | Alive | node_manager_locator...
Login with user ORCLADMIN and the password you specified for IAS_ADMIN.
ContentDB interface let you upload and download files. You can use it to keep your documentation in a single location. It has versioning capabilities too.
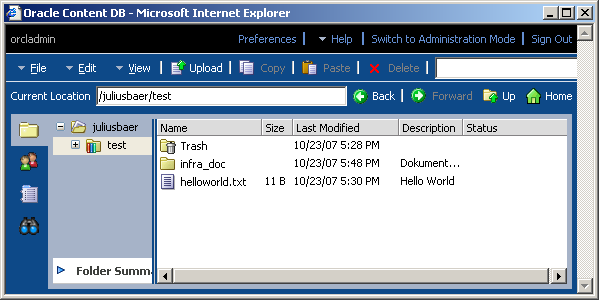
Oracle Database Download
I just read on Renaps Blog that Oracle 11g for Windows is out.
Oracle Database Download
Oracle OpenWorld will host the

On the wiki.oracle.com Wiki, you can create your own unconference session.
I have proposed a session about SQL Model :
SQL Model
Niall Litchfield just wrote about 11g availability on 64bits linux.
Happy Birthday Niall
Download Oracle Database
Oracle Support started a series about database internals.
|
||||||||
|
Nan
select
BINARY_DOUBLE_INFINITY INF,
BINARY_DOUBLE_NAN NAN,
greatest(BINARY_DOUBLE_INFINITY, BINARY_DOUBLE_NAN) GRE
from t;
INF NAN GRE
--- --- ---
Inf Nan Nan
Nan means not a number. It could be square root of -1, log of -1, 0/0, acos(1000), Inf-Inf, etc…
select
SQRT(-1d),
LN(-1d),
0/0d,
acos(1000d),
BINARY_DOUBLE_INFINITY-BINARY_DOUBLE_INFINITY
from t;
SQR LN- 00D ACO BIN
--- --- --- --- ---
Nan Nan Nan Nan Nan
According to the doc, it is greater than any value, inclusive positive infinity.
To check if a value is nan, it could be compared to BINARY_DOUBLE_NAN.
where :z = BINARY_DOUBLE_NAN
There is a function NANVL(:z, :y) which evaluates to :y when :z is equal Nan. if :z is not equal to Nan and :y is not null, then it evaluates to :z. NANVL evaluates to NULL when :z or :y is null.
select NANVL(1,null) from dual;
NANVL
------
[null]
I have a table with a blob
create table t(b blob);
insert into t values ('585858');
In 11g sql*plus, I can display raw data
select b from t;
B
------
585858
Ok, but if I want to display XXX (the character content)
select utl_raw.cast_to_varchar2(b) from t;
UTL
---
XXX
However, in sql, a raw cannot be more than 2000 bytes long.
Another way to print your blob content is to use DBMS_LOB.CONVERTTOCLOB
var c clob
set autoprint on
declare
b blob;
dest_offset integer := 1 ;
src_offset integer := 1 ;
lang_context integer:= 1 ;
warning integer;
begin
select b into b from t for update;
dbms_lob.createtemporary(:c,true);
dbms_lob.converttoclob(
:c, b, DBMS_LOB.LOBMAXSIZE,
dest_offset, src_offset,
1, lang_context, warning);
end;
/
C
---
XXX
Addition is supposed to be associative.
a+(b+c)=(a+b)+c
This may be wrong in Oracle when dealing with months and days
with t as (select
interval '1' month a,
date '2007-09-26' b,
interval '7' day c
from dual)
select a+(b+c),(a+b)+c
from t;
A+(B+C) (A+B)+C
----------- -----------
03-NOV-2007 02-NOV-2007
The equality is supposed to be transitive
if (a=b and b=c) then (a=c)
However, in Oracle the comparison operator equal may imply some transformation
with t as (select '.0' a, 0 b, '0.' c from dual)
select
case when a=b then 'YES' else 'NO ' end "A=B",
case when b=c then 'YES' else 'NO ' end "B=C",
case when a=c then 'YES' else 'NO ' end "A=C"
from t;
A=B B=C A=C
--- --- ---
YES YES NO
The equality operator is also supposed to be reflexive
a=a
This is unfortunately wrong with null
with t as (select null a from dual)
select case when a=a then 'YES' else 'NO ' end "A=A"
from t;
A=A
---
NO

I have start building my schedule. There are about 1722 sessions to chose from this year, so choice is difficult!
Due to jet-lag, I mostly cannot do all what I planed. And I also like to spent some time by the exhibitors and the boosts.
Ok, the one I will not miss :
Steven Feuerstein : Break Your Addiction to SQL!
Amit Ganesh : Oracle Database 11g: The Next-Generation Data Management Platform
Bryn Llewellyn : Doing SQL from PL/SQL: Best and Worst Practices
Thomas Kyte : The Top 10–No, 11–New Features of Oracle Database 11g
Lucas Jellema : The Great Oracle SQL Quiz
I have been to a SOUG last Thursday.
We first had a presentation from Thomas Koch about performance in Zurich Kantonalbank. As I have been working as a DBA for about two years in that bank, I already had my opinion about performance there 😕
The second presentation was about TimesTen. I must say I have never used Times Ten. So I was glad to hear Stefan Kolmar from Oracle presenting the product. Ok, here it is in a few lines.
In TimesTen, the whole database is in the memory. TimesTen is an Oracle Product and a Database, but it is not an Oracle Database. The objective must be to have a response time in microseconds and hundred of thousands of transactions per second. You have a log buffer, and you can decide to asynchronously dump the buffer to file.
Let me try to explain the example from Stefan :
You have a mobile phone company. Foreign call can be fairly expensive, so those transactions will be synchronously dumped to the disk. Local calls cost about 1 Euro in average. So if you dump the log to disk every ten transactions, in case of a failure an average of 5 Euros will not be billed. In this way you can select the transaction to have synchronous and the one to have asynchronous. It looks promising, but probably not for critical businesses like banking where you are required to guarantee zero data-loss.
There is an additional functionality in TimesTen which is called “cache for Oracle”. It is a layer between the client and the database. It does not offer the same functionality as Oracle. For example, you cannot do PL/SQL. But it may offer microsecond access.
I will document two examples :
1) read only
You have a flight reservation company. Flight reservation are very important, so they will be in the database (no data loss). Flight schedule are read-only for the client. They will be cached in TimesTen. So when accessing the timetables, it will be ultra-fast. When booking, it may take a few seconds.
2) on demand
You have a call center. When a customer phone, all data relative to the customer (history, name, contracts, contract details) are immediately loaded from the database in TimesTen. So when the Call Center employee asks for any info, they are immediately available
How much does it cost? Check on store.oracle.com
For a tiny database up to 2Gb it is 6000$/processor for 3 years. More options, more money…
Today I opened two SR about flashback archive in 11g. In one of them, I complained that user SCOTT was not allowed to create a flashback archive. In the doc that I downloaded a few weeks ago I read :
Prerequisites
You must have the FLASHBACK ARCHIVE ADMINISTER system privilege to create a flashback data archive. This privilege can be granted only by a user with DBA privileges. In addition, you must have the CREATE TABLESPACE system privilege to create a flashback data archive, as well as sufficient quota on the tablespace in which the historical information will reside.
So as I was getting an ORA-55611, I opened a SR. The support engineer pointed me to the online documentation where I was astonished to read :
Prerequisites
You must have the FLASHBACK ARCHIVE ADMINISTER system privilege to create a flashback data archive. In addition, you must have the CREATE TABLESPACE system privilege to create a flashback data archive, as well as sufficient quota on the tablespace in which the historical information will reside. To designate a flashback data archive as the system default flashback data archive, you must be logged in as SYSDBA.
Well, Read The Fine Online Manual !!!
The second tar is related to long retention (about the age of the earth)
SQL> alter flashback archive fba01
modify retention 4106694757 year;
Flashback archive altered.
SQL> select retention_in_days
from DBA_FLASHBACK_ARCHIVE;
RETENTION_IN_DAYS
-----------------
1
I tried this in 11g
TABLE T
| X |
|---|
| 123 |
| -1.2e-3 |
| abc |
select x,
to_number(
xmlquery('number($X)'
passing x as x
returning content)) n
from t;
X N
------- ----------
123 123
-1.2e-3 -.0012
abc
it is quite a common task to extract numbers from varchar2 and to dig out poor quality data.
select x, to_number(x) from t;
ERROR:
ORA-01722: invalid number
A well-known PL/SQL approach would be to use exception. Ex:
create or replace function f(x varchar2)
return number is
begin return to_number(x);
exception when others then return null;
end;
/
select x, f(x) n from t;
X N
------- ----------
123 123
-1.2e-3 -.0012
abc
another approach in plain sql could involve CASE and REGEXP
select x,
case when
regexp_like(x,
‘^-?(\+\.?|\d*\.\d+)([eE][+-]\d+)?$’)
then to_number(x)
end n
from t;
X N
——- ———-
123 123
-1.2e-3 -.0012
abc
Download oracle-oid-10.1.4.2.0-1.0.i386.rpm
Download oracle-xe-univ-10.2.0.1-1.0.i386.rpm
Install the rpm
# rpm -i oracle-*.i386.rpm
In SLES 10, there is no /bin/cut, let’s create a link as root to avoid a mistake when running config-oid.sh
# ln -s /usr/bin/cut /bin/cut
Run the configure script as root
# /etc/init.d/oracle-oid configure
That’s all folks! It created an Oracle XE 10gR2 database, and configured a running database. Excellent!
LDAP Server is running and configured.
$ ldapsearch cn=orcladmin dn
cn=orcladmin, cn=Users, dc=com
There is a nice video to run on linux : oracleauthenticationservices_demo.vvl
Save the file, set the display, then
$ chmod +x oracleauthenticationservices_demo.vvl
$ ./oracleauthenticationservices_demo.vvl
It shows also how to use Oracle LDAP Server OID to identify your Linux users with the preview of Oracle Authentication Service
I am always delighted to read the top features by Arup Nanda.
He started his 11g series : Oracle Database 11g: The Top Features for DBAs and Developers
There are many partitioning enhancements. The most exciting feature for me is the INTERVAL partitioning. A huge cause of downtime and waste of storage is the range partitioning. In 10g and before, a partitioning by dates required that the partition are defined before values are inserted.
Now we have automatic partition creation 😀
create table t(d date)
partition by range(d)
interval(interval '1' month)
(partition p1 values less than (date '0001-01-01'));
One partition must be created manually, here the partition will contain all dates from 1-JAN-4712BC to 31-DEC-0000 (which is not a legal date by the way)
There is also new syntax to query the partition
SQL> insert into t values (date '2000-01-10');
1 row created.
SQL> insert into t values (date '2000-01-20');
1 row created.
SQL> insert into t values (date '2000-03-30');
1 row created.
SQL> select * from t partition for (date '2000-01-01');
D
-------------------
10.01.2000 00:00:00
20.01.2000 00:00:00
Note the syntax can be used in any form of partitioning. Here in a list-list composite
SQL> create table t(x number, y number)
partition by list(x)
subpartition by list(y)
subpartition template (
subpartition sp1 values(1),
subpartition sp2 values(2))
(partition values(1), partition values(2));
Table created.
SQL> insert into t values(1,2);
1 row created.
SQL> select * from t subpartition for (1,2);
X Y
---------- ----------
1 2
Ok, one more feature Arup introduced is the REF partitioning, where you have a schema with both the parent and child tables partitioned, and you want to partition on a column of the parent table that is not in the child table (as you had bitmap join indexes, you have now ref partitions). Check it on his site.
Finally Arup explained SYSTEM partitioning, which is not inconceivable, but will hardly be used.
Imagine you have a table containing just one single LOB column, and a LOB cannot be used as a partition key.
SQL> create table t(x clob)
partition by system (
partition p1,
partition p2,
partition p3,
partition p4);
Table created.
So far this seems fine. So what the problem? You cannot insert in that table!
SQL> insert into t values(1);
insert into t values(1)
*
ERROR at line 1:
ORA-14701: partition-extended name or bind variable
must be used for DMLs on tables partitioned by the
System method
so you must define in which partition you want to add data. For example round robin. Or random. Whatever.
SQL> insert into t partition (P1) values ('x');
1 row created.
SQL> insert into t partition (P2) values ('y');
1 row created.
If you want to use bind variable, you can use dataobj_to_partition
SQL> select object_id
from user_objects
where object_name='T'
and subobject_name is not null;
OBJECT_ID
----------
55852
55853
55854
55855
SQL> var partition_id number
SQL> exec :partition_id := 55852
PL/SQL procedure successfully completed.
SQL> insert into t
partition (dataobj_to_partition("T",:partition_id))
values ('x');
1 row created.
SQL> exec :partition_id := 55853
PL/SQL procedure successfully completed.
SQL> insert into t
partition (dataobj_to_partition("T",:partition_id))
values ('x');
1 row created.
Actually, SYSTEM partitioning is misleading, YOU are responsible for choosing the partition in which you want to insert, not the system
One of the problem with flashback queries in 10g and before is that you never know if it will works, especially you cannot expect to have flashback queries working for very old tables.
Let’s imagine you want to export your CUSTOMER as of 30/6/2007. No chance in 10g…
Well, with 11g, you can create a flashback archive, and it will save all change until end of retention (many years if you want).
Here it is :
SQL> connect / as sysdba
Connected.
SQL> create tablespace s;
Tablespace created.
SQL> create flashback archive default fba01 tablespace s
retention 1 month;
Flashback archive created.
SQL> connect scott/tiger
Connected.
SQL> create table t(x number) flashback archive;
Table created.
SQL> host sleep 10
SQL> insert into t(x) values (1);
1 row created.
SQL> commit;
Commit complete.
SQL> SELECT dbms_flashback.get_system_change_number FROM dual;
GET_SYSTEM_CHANGE_NUMBER
------------------------
337754
SQL> update t set x=2;
1 row updated.
SQL> commit;
Commit complete.
SQL> select * from t as of scn 337754;
X
----------
1
SQL> alter table t no flashback archive;
Table altered.
SQL> drop table t;
Table dropped.
SQL> select FLASHBACK_ARCHIVE_NAME, RETENTION_IN_DAYS,
STATUS from DBA_FLASHBACK_ARCHIVE;
FLASHBACK_ARCHIVE_NAME RETENTION_IN_DAYS STATUS
---------------------- ----------------- -------
FBA01 30 DEFAULT
SQL> connect / as sysdba
Connected.
SQL> drop flashback archive fba01;
Flashback archive dropped.
SQL> drop tablespace s;
Tablespace dropped.
note that a month is 30 days. If you try to create a flashback archive in a non-empty tablespace you may get
ORA-55603: Invalid Flashback Archive command
which is not a very helpful message
What is wrong with this query?
select*from"EMP"where'SCOTT'="ENAME"and"DEPTNO"=20;
EMPNO ENAME JOB MGR HIREDATE
---------- ---------- --------- ---------- ---------
7788 SCOTT ANALYST 7566 13-JUL-87
It is a zero-space query 😎
You could write it as
select
*
from
"EMP"
where
'SCOTT'="ENAME"
and
"DEPTNO"=20;
personnaly, I would write it as
select *
from emp
where ename='SCOTT'
and deptno=20;
Formatting is very important, it makes your code nice to read and indentation make the blocks visualable.
Auto-formatting is also fine, but I like to decide myself if the line is too long, or if I want to have FROM and EMP on the same line.
Have a look at the free online SQL Formatter SQLinForm
I have read a long long time ago the following note on positive infinity http://www.ixora.com.au/notes/infinity.htm
Today I finally succeeded in inserting positive infinity in a number field
create table t as select
STATS_F_TEST(cust_gender, 1, 'STATISTIC','F') f
from (
select 'M' cust_gender from dual union all
select 'M' from dual union all
select 'F' from dual union all
select 'F' from dual)
;
I am so happy 😀
Let’s try a few queries
SQL> desc t
Name Null? Type
----------------- -------- ------
F NUMBER
SQL> select f from t;
F
----------
~
SQL> select f/2 from t;
select f/2 from t
*
ERROR at line 1:
ORA-01426: numeric overflow
SQL> select -f from t;
-F
----------
-~
SQL> select cast(f as binary_double) from t;
CAST(FASBINARY_DOUBLE)
----------------------
Inf
SQL> select * from t
2 where cast(f as binary_double) = binary_double_infinity;
F
----------
~
Now expect a lot of bugs with your oracle clients 😎
Toad 9 for example returns
SQL> select f from t
select f from t
*
Error at line 1
OCI-22065: number to text translation for the given
format causes overflow
The use of a referential integrity constraint is to enforce that each child record has a parent.
SQL> CREATE TABLE DEPT
2 (DEPTNO NUMBER PRIMARY KEY,
3 DNAME VARCHAR2(10)) ;
Table created.
SQL> CREATE TABLE EMP
2 (EMPNO NUMBER PRIMARY KEY,
3 ENAME VARCHAR2(10),
4 DEPTNO NUMBER
5 CONSTRAINT EMP_DEPT_FK
6 REFERENCES DEPT(deptno));
Table created.
SQL> INSERT INTO DEPT(deptno,dname) VALUES
2 (50,'CREDIT');
1 row created.
SQL> INSERT INTO EMP(EMPNO,ENAME,DEPTNO) VALUES
2 (9999,'JOEL',50);
1 row created.
SQL> COMMIT;
Commit complete.
SQL> DELETE DEPT WHERE DEPTNO=50;
DELETE DEPT WHERE DEPTNO=50
*
ERROR at line 1:
ORA-02292: integrity constraint (SCOTT.EMP_DEPT_FK) violated
- child record found
I cannot delete this department, because the department is not empty. Fortunately ❗
Let’s redefine the constraint with a DELETE CASCADE clause
SQL> alter table emp drop constraint emp_dept_fk;
Table altered.
SQL> alter table emp add constraint emp_dept_fk
2 foreign key (deptno) references dept(deptno)
3 on delete cascade;
Table altered.
SQL> DELETE DEPT WHERE DEPTNO=50;
1 row deleted.
SQL> select * from emp where ename='JOEL';
no rows selected
Note the line 1 row deleted. This is evil 👿 I have deleted a department, and there were employees in it, but I got no error, no warning and no feedback about the DELETE EMP.
Instead of improving the data quality, the ON DELETE CASCADE foreign key constraint here silently deleted rows. Joel will once phone you and ask why he has been deleted…
There is one more clause of the foreign key which sets the refering column to null
SQL> INSERT INTO DEPT(deptno,dname) VALUES
2 (60,'RESTAURANT');
1 row created.
SQL> INSERT INTO EMP(EMPNO,ENAME,DEPTNO) VALUES
2 (9998,'MARC',60);
1 row created.
SQL> alter table emp drop constraint emp_dept_fk;
Table altered.
SQL> alter table emp add constraint emp_dept_fk
2 foreign key (deptno) references dept(deptno)
3 on delete set null;
Table altered.
SQL> DELETE DEPT WHERE DEPTNO=60;
1 row deleted.
SQL> select * from emp where ename='MARC';
EMPNO ENAME DEPTNO
---------- ---------- ----------
9998 MARC
Marc has no department, because his department has been deleted. Again, no feedback, no warning, no error.
Instead of improving the data quality, the ON DELETE SET NULL foreign key constraint here silently updated rows columns to NULL. Marc will wonder why he get no invitation to the department meetings.
What could be worse???
Triggers of course! Triggers not only removes rows in child tables, but triggers can also do very weird things, like updating another table, changing the values you are trying to insert, outputing a message, etc.
Also triggers are programmed by your colleagues, so they must be full of bugs 😈
You cannot imagine the number of problems that are caused by triggers and revealed only when tracing.
I once had something like
SQL> CREATE INDEX I ON T(X);
P07431B processed
Well, after enabling the trace, I discover one trigger fired on any ddl and the trigger was doing nothing else than this distracting dbms_output for “debugging” purpose. Guess google and metalink for the message did not help much…
This is a very neat feature in 11g.
I have a script called foo.sql
create table t(x number primary key);
insert into t(x) values (1);
insert into t(x) values (2);
insert into t(x) values (2);
insert into t(x) values (3);
commit;
It is eyes-popping that this script will return an error, but which one?
Let’s errorlog !
SQL>set errorl on
SQL> @foo
Table created.
1 row created.
1 row created.
insert into t(x) values (2)
*
ERROR at line 1:
ORA-00001: unique constraint (SCOTT.SYS_C004200) violated
1 row created.
Commit complete.
SQL> set errorl off
SQL> select timestamp,script,statement,message from sperrorlog;
TIMESTAMP SCRIPT STATEMENT
---------- ------- ---------------------------
MESSAGE
---------------------------------------------------------
11:18:56 foo.sql insert into t(x) values (2)
ORA-00001: unique constraint (SCOTT.SYS_C004200) violated
There is also a huge bonus 😀
You can use it with 9i and 10g databases too! Only the client must be 11g. To download the 11g client only, go to Oracle E-Delivery Website
Even small, this is one of my favorite new features!
By reading Pete Finnigan’s Oracle security weblog today, I discovered that the password is no longer displayed in DBA_USERS in 11g.
select username,password
from dba_users
where username='SCOTT';
USERNAME PASSWORD
-------- ------------------------------
SCOTT
select name,password
from sys.user$
where name='SCOTT';
NAME PASSWORD
----- ------------------------------
SCOTT F894844C34402B67
on the one hand, it is good for the security.
On the other hand, it is a huge change which is not documented (I immediately sent comments to the Security and Reference book authors) and it will make a lot of script failing (scripts that use to change the password to log in and change it back to the original value afterwards).
Protecting the hash is extremely important, check your scripts for 11g compatibility!
